Claude Fable 5 완전 정리 — Mythos급 성능, 폴백형 세이프가드, 그리고 개발자가 지금 해야 할 일
목차
2026년 6월 9일, Anthropic이 새 모델 Claude Fable 5와 Claude Mythos 5를 발표하고 제공을 시작했어요. 이 소식은 Hacker News에서 1,102포인트를 얻으며 AI 커뮤니티에 큰 반향을 일으켰죠. 과거 Claude 3.5 Sonnet이나 4.0계 출시 때와 비교해도 두드러진 수치예요.
이 글에서는 Fable 5의 정체와 성능, 독특한 세이프가드 구조, 가격과 제공 일정, 그리고 API를 쓰는 개발자가 지금 바로 확인해야 할 마이그레이션 포인트와 프롬프트 작성법까지 한 번에 정리합니다.
이 글의 대상 독자
- Anthropic API를 탑재한 애플리케이션을 개발·운영하는 엔지니어
- 모델 선정을 맡은 AI 프로덕트 매니저·아키텍트
- Claude용 프롬프트를 작성·개선하고 싶은 분
- 조사나 개발 같은 장시간 작업을 AI 에이전트에게 맡기고 싶은 분
Fable 5란 무엇인가 — Mythos 클래스의 첫 일반 공개 모델
Fable 5는 Anthropic이 새로 만든 최상위 티어 'Mythos 클래스(Mythos-class)'에 속하는 첫 일반 제공 모델이에요. 공식 설명에 따르면 Mythos 클래스는 "Opus 클래스를 능력 면에서 넘어서는 Claude 모델 계층"입니다.
경위를 간단히 돌아볼게요. Anthropic은 올해 4월에 프런티어 모델 'Claude Mythos Preview'를 발표했지만, 사이버 공격 악용 리스크(취약점 발견·악용 능력이 극히 높음)를 이유로 일반 공개를 보류했어요. 대신 미국 정부와 연계한 'Project Glasswing'을 통해 사이버 방어 조직과 핵심 인프라 기업 등 한정된 파트너에게만 제공해 왔죠. 이번에 그 모델이 Fable 5라는 이름으로 처음 일반 공개된 거예요.
Fable 5와 Mythos 5의 차이
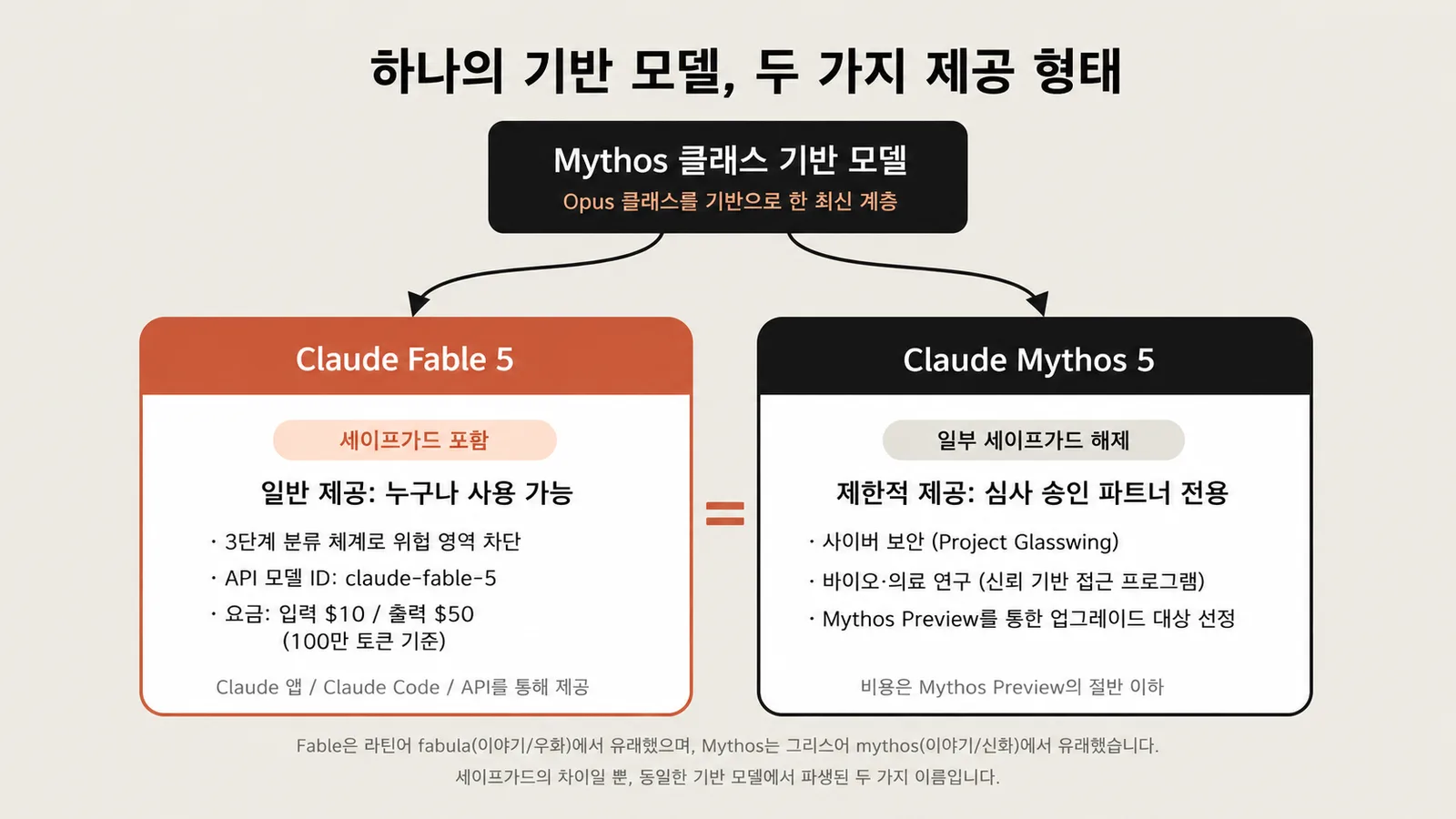
이번 발표의 가장 큰 특징은, 둘이 속은 완전히 같은 모델이고 세이프가드(안전장치) 유무만 다르다는 점이에요.
- Claude Fable 5: 세이프가드를 내장해 누구나 쓸 수 있는 일반 제공 버전
- Claude Mythos 5: 일부 영역의 세이프가드를 해제하고, Project Glasswing 심사를 통과한 조직에만 제공
즉 '모델 자체는 같고, 안전 제한의 유무와 제공 대상이 다르다'는 구성이죠. 이름의 유래도 재미있는데, Fable은 라틴어 fabula(이야기되는 것)에서 왔고 그리스어 mythos와 가까운 뜻이라고 하네요.
Claude 모델 패밀리 전체 구도(2026년 6월 기준)
| 모델 | 모델 ID | 시리즈 |
|---|---|---|
| Claude Fable 5 | claude-fable-5 | Mythos 클래스(최상위·신규) |
| Claude Opus 4.8 | claude-opus-4-8 | 4.X(고성능) |
| Claude Sonnet 4.6 | claude-sonnet-4-6 | 4.X(범용 밸런스) |
| Claude Haiku 4.5 | claude-haiku-4-5-20251001 | 4.X(고속·경량) |
4.X 패밀리가 '중량급·범용·경량 고속'으로 역할을 나누고 있었다면, Fable 5는 그 위에 새로 얹힌 최상위 모델이에요.
성능: 거의 모든 벤치마크에서 SOTA
공식 발표에 따르면 Fable 5는 지금까지 일반 제공된 어떤 모델보다 높은 능력을 갖추었고, 소프트웨어 엔지니어링, 지식 노동, 비전, 과학 연구 등 테스트한 거의 모든 벤치마크에서 최고 수준(state-of-the-art)을 달성했어요. 작업이 길고 복잡해질수록 다른 모델과의 격차가 벌어지고, 자율적으로 가동하는 시간도 역대 Claude 모델 가운데 가장 깁니다.
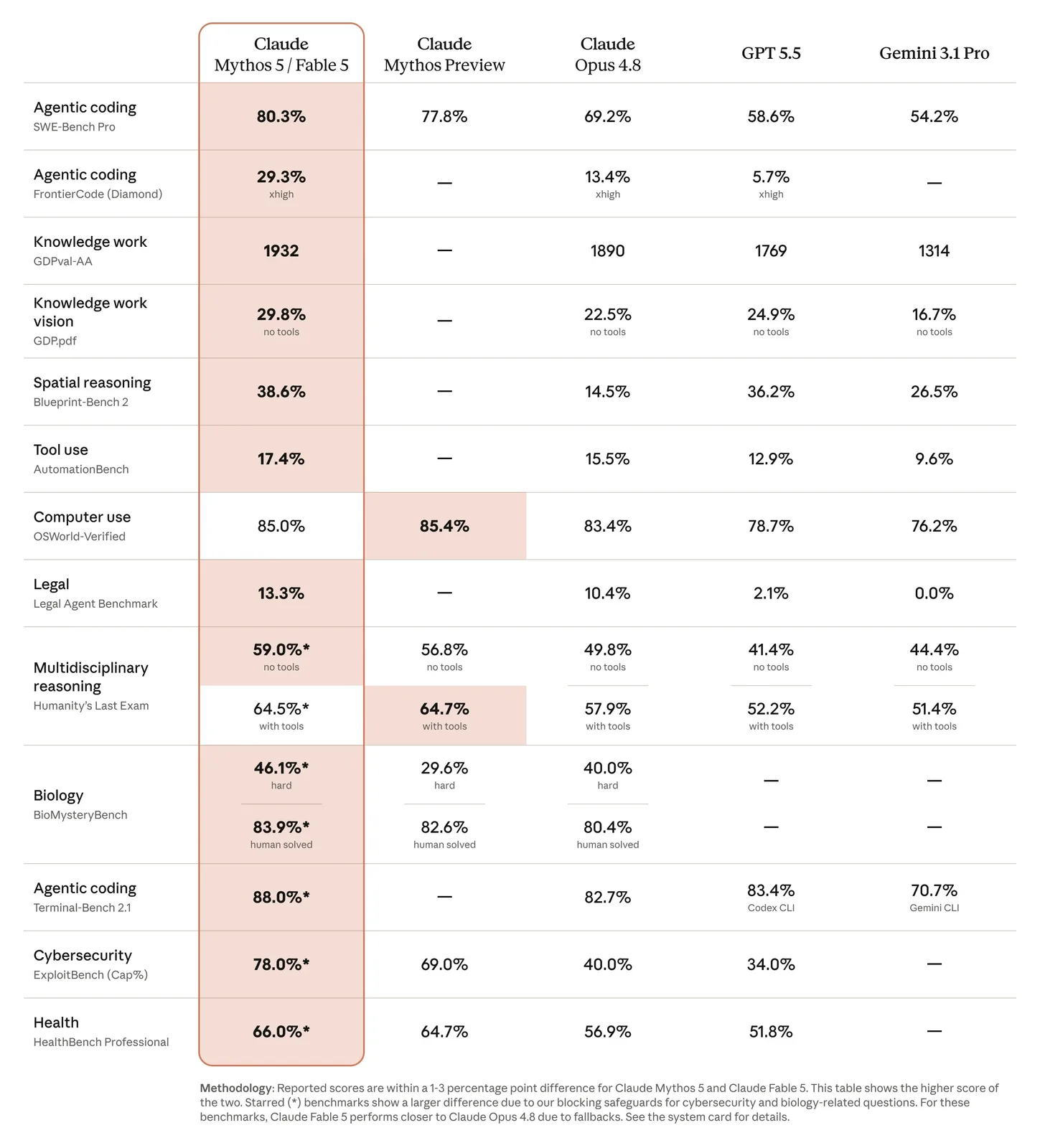 출처: Anthropic 공식 발표 벤치마크 표
출처: Anthropic 공식 발표 벤치마크 표
숫자로 보면 이래요. 실무에 가까운 코딩 과제를 측정하는 SWE-Bench Pro에서 80.3%. Opus 4.8(69.2%)을 10포인트 이상, GPT-5.5(58.6%)와 Gemini 3.1 Pro(54.2%)를 20포인트 이상 앞선 수치예요.
공식에 실린 실제 사례도 인상적입니다.
- 소프트웨어 엔지니어링: 조기 테스트에서 Stripe가 5,000만 줄 규모의 Ruby 코드베이스 전체 마이그레이션을 Fable 5로 하루 만에 완료했다고 보고했어요. 사람이 하면 팀 단위로 2개월 이상 걸리는 작업이죠.
- 비전: 스크린샷만으로 웹 앱의 소스 코드를 재구축할 수 있어요. 기존 모델이 보조 도구를 붙여도 고전하던 '포켓몬스터 파이어레드'를, 지도나 게임 내부 상태 정보 없이 화면 정보만 주는 최소한의 하네스로 클리어했습니다. 플레이 타임랩스 영상은 공식 페이지에서 볼 수 있어요.
- 장문 컨텍스트·메모리: 수백만 토큰 규모의 장시간 작업에서도 집중을 유지하고, 스스로 남긴 메모를 활용해 출력을 개선해요. 덱 빌딩 게임 'Slay the Spire'를 플레이하게 한 사례에서는 파일에 메모를 남기며 플레이를 이어 갔고, Opus 4.8보다 성적이 크게 좋아졌으며 최종 Act 도달 횟수도 늘었다고 합니다.
기존 Claude보다 훨씬 오래, 훨씬 자율적으로 일을 이어 간다는 얘기죠.
세이프가드 구조: '거부'가 아니라 '폴백'
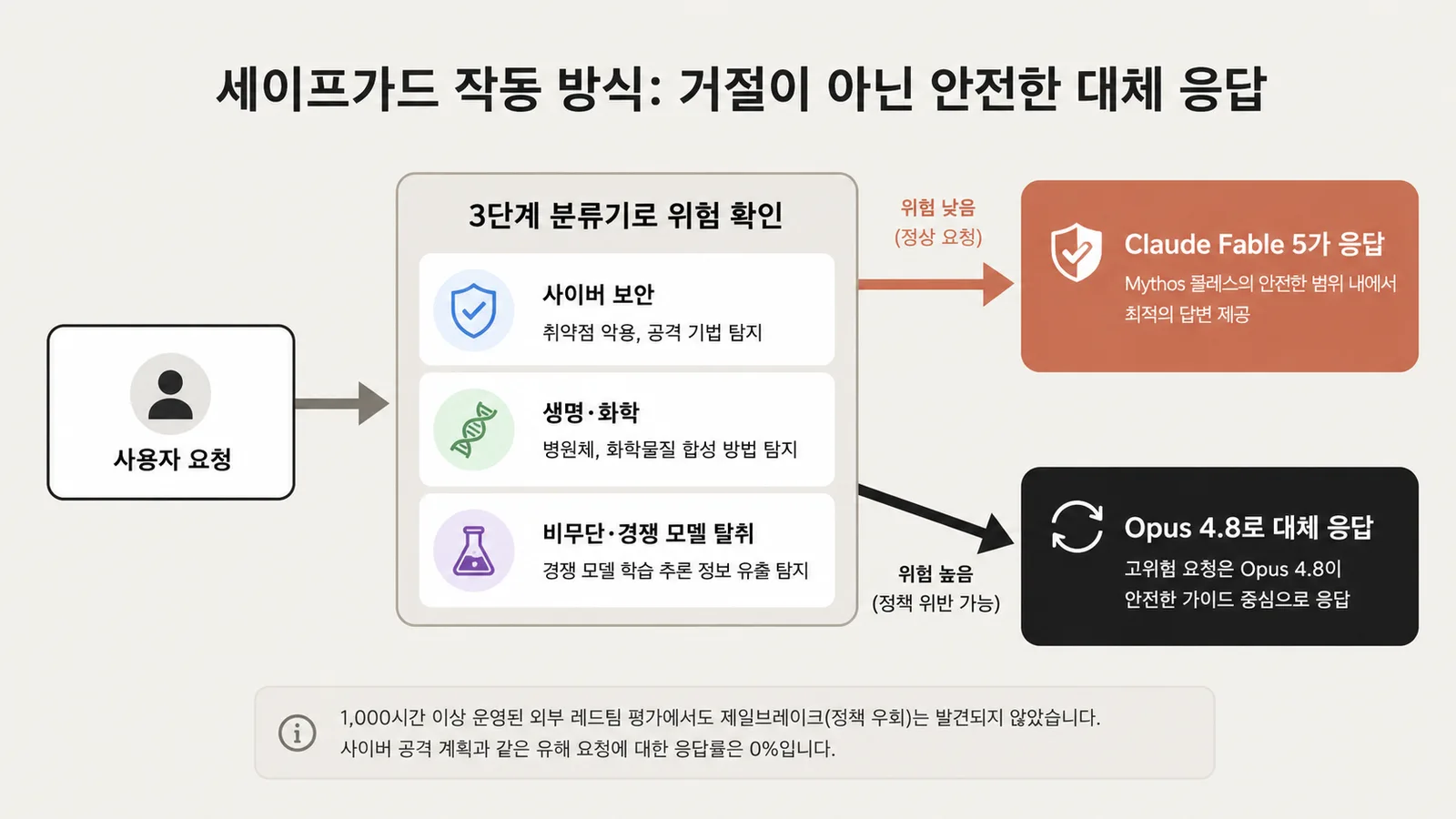
능력이 이 정도로 높으면 악용됐을 때 피해도 커지겠죠. 그래서 Fable 5에는 메인 모델과 별개의 AI 시스템인 분류기(classifier)가 들어 있어서, 다음 3개 영역에 관한 요청을 감지해요.
- 사이버 보안(취약점 발견·악용, 에이전트형 해킹 행위 등)
- 생물학·화학
- 증류(distillation, 모델 능력의 무단 추출)
분류기가 반응하면 요청이 거부되는 게 아니라, 차순위 고성능 모델인 Claude Opus 4.8로 자동 폴백되어 응답이 생성됩니다. 전환이 일어나면 사용자에게 알려 주는 구조죠. '거부가 아니라 폴백'이라는 설계는 UX 관점에서 꽤 합리적이라고 느껴요.
초기 데이터에서 폴백이 발생하는 비율은 평균적으로 세션의 5% 미만. 분류기는 의도적으로 보수적으로 튜닝되어 있어서 무해한 요청이 오탐되는 경우도 있다는 걸 Anthropic 스스로 인정했고, 앞으로 오탐(False Positive)을 줄여 가겠다고 밝혔어요.
안전성 검증도 만만치 않았는데, 외부 버그 바운티 프로그램에서 1,000시간 이상 테스트를 진행했지만 유니버설 탈옥(모든 제한을 뚫는 수법)은 발견되지 않았다고 보도됐어요. 사이버 공격 계획·익스플로잇 개발·방어 우회를 요구하는 단일 질문에는 한 번도 응하지 않았다고 합니다.
가격과 제공 일정
- API 가격: 입력 $10 / 100만 토큰, 출력 $50 / 100만 토큰. 환율 1달러 = 1,400원 가정 시 100만 토큰당 입력 약 1만 4,000원, 출력 약 7만 원이에요.
- 컨텍스트 윈도우: 100만 토큰, 최대 출력 128K 토큰
- 제공 경로: Claude API, Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry
Opus 4.8 대비 약 2배 가격이지만, Mythos Preview 시절(Opus의 5배)보다는 크게 내려갔어요.
구독 플랜에는 단계적인 제공 일정이 예고되어 있습니다.
| 기간 | 제공 형태 |
|---|---|
| 6월 9일~22일 | Pro / Max / Team / 시트 기반 Enterprise에 추가 요금 없이 포함 |
| 6월 23일 이후 | 위 플랜에서 일단 제외, 이용하려면 사용 크레딧 필요 |
| 충분한 제공 용량 확보 시 | 구독 플랜 재포함 목표 |
한 가지 알아 둘 점. Mythos 클래스 모델은 모든 이용 트래픽을 30일간 의무적으로 보존해요. 다만 학습에는 쓰지 않고 안전성 향상 목적으로만 쓴다고 설명했습니다.
개발자 가이드: 마이그레이션과 주의점
지금 바로 해야 할 일
- 공식 문서 확인 — Anthropic API 문서에서 Fable 5의 상세 사양(컨텍스트 윈도우, 가격, 레이트 리밋)을 확인한다.
- API 접근 검증 —
claude-fable-5모델 ID가 자신의 API 플랜에서 사용 가능한지 테스트한다. - 유스케이스 적합성 평가 — 기존 4.X 패밀리와의 사용 구분을 검토한다.
모델 이전을 검토할 때는 먼저 테스트 환경에서 claude-fable-5의 출력 품질·지연 시간·비용을 실제 유스케이스로 평가해 보세요. 운영 환경 적용은 검증 후에 하는 게 안전합니다.
코드 예제: 모델 ID만 바꾸면 끝
Anthropic Python SDK 기준으로, 기존 코드에서 모델 ID만 교체하면 바로 쓸 수 있어요.
Before(기존 Sonnet 모델 사용 시)
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6", # 기존 모델
max_tokens=1024,
messages=[
{"role": "user", "content": "Explain the difference between supervised and unsupervised learning."}
]
)
print(response.content[0].text)
After(Claude Fable 5 사용 시)
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-fable-5", # 새로운 Fable 시리즈
max_tokens=1024,
messages=[
{"role": "user", "content": "Explain the difference between supervised and unsupervised learning."}
]
)
print(response.content[0].text)
이전 부담이 적은 잘된 설계죠. 여러 모델의 출력을 비교 평가하고 싶다면 이런 A/B 테스트 스크립트를 준비해 두면 유스케이스별 최적 모델 선정이 한결 수월해집니다.
import anthropic
client = anthropic.Anthropic()
models = [
"claude-fable-5",
"claude-sonnet-4-6",
"claude-opus-4-8",
]
prompt = "Summarize the key principles of clean code in 3 bullet points."
for model_id in models:
response = client.messages.create(
model=model_id,
max_tokens=512,
messages=[{"role": "user", "content": prompt}]
)
print(f"=== {model_id} ===")
print(response.content[0].text)
print()
⚠️ 마이그레이션 시 반드시 점검할 4.X와의 차이
공식 문서에서 이미 확인된 차이가 있으니, 운영 적용 전에 다음 세 가지를 점검하세요.
thinking: {"type": "disabled"}는 지원되지 않습니다. 지정하면 400 오류를 반환해요. Fable 5는 Adaptive Thinking이 항상 켜져 있거든요.- 안전 분류기가 작동하면 HTTP 200이면서
stop_reason: "refusal"로 응답이 돌아올 수 있어요. 상태 코드만으로 성공을 판정하는 파서는 수정이 필요합니다. - 모든 트래픽에 30일 데이터 보존이 적용되며, 제로 데이터 보존(ZDR)은 사용할 수 없습니다. 데이터 정책이 엄격한 프로젝트라면 사전 검토가 필수예요.
특히 2번은 실무에서 바로 부딪힐 수 있는 부분이에요. 거부를 받았다면 분류기를 우회하려 하지 말고 의뢰의 목적과 범위를 다시 살펴보세요. 정당한 방어 목적의 작업이라면 대상 시스템, 허가된 범위, 기대하는 방어적 결과물을 명확히 하는 게 중요합니다.
프롬프트 작성법: 절차가 아니라 '일의 조건'을 건넨다
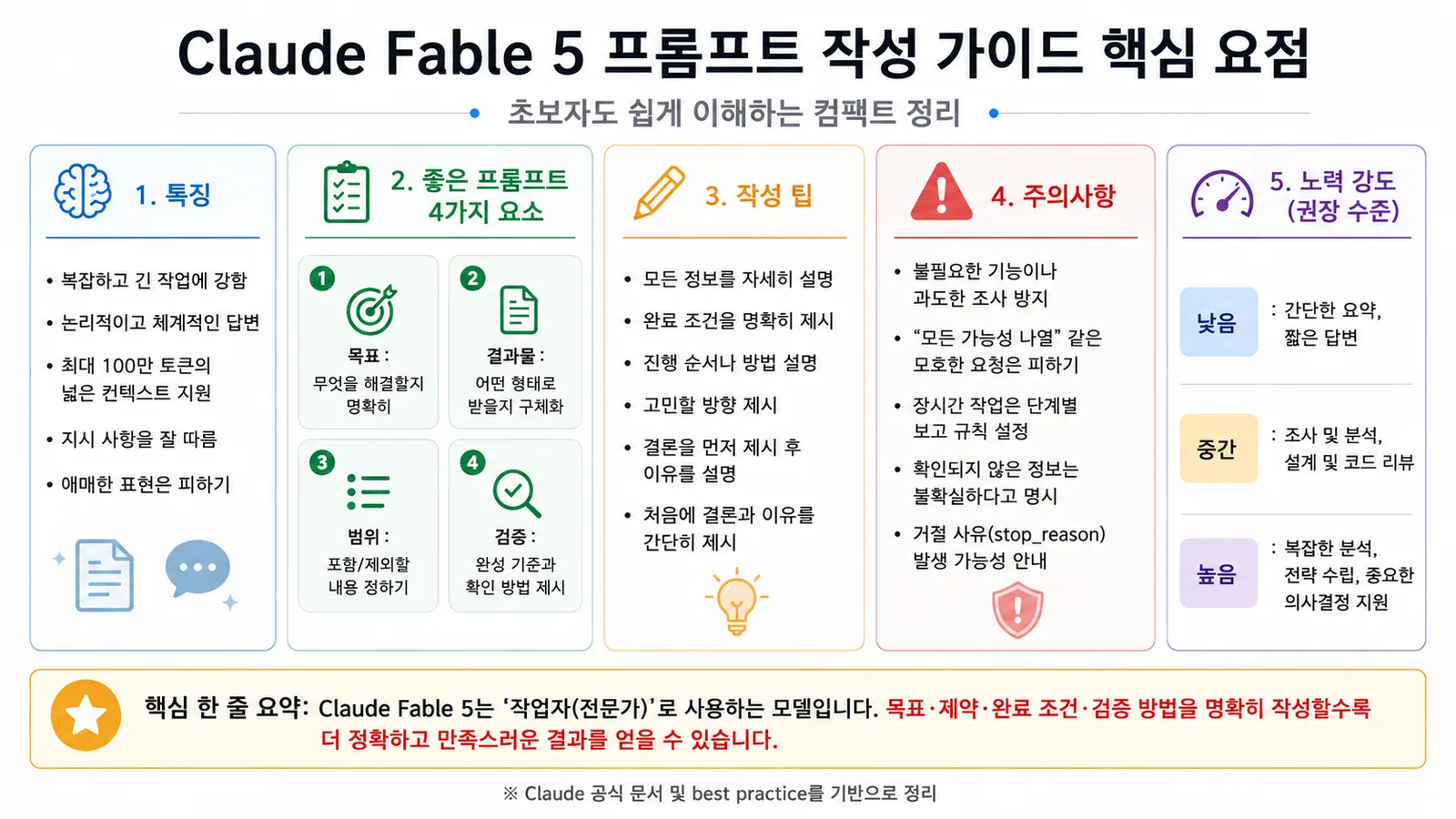
여기서부터는 Fable 5를 실제로 부려 먹는 방법이에요. 지금까지의 생성 AI가 질문을 입력하고 답변을 받는 '일문일답' 중심이었다면, Fable 5는 조사, 설계, 구현, 검증 같은 여러 단계를 하나의 일로 묶어 맡기는 사용 방식을 염두에 두고 있어요. 예를 들면 이런 작업이죠.
- 대량의 명세서와 소스 코드를 읽고 변경할 부분을 찾아낸다
- 구현 방침을 세우고 코드를 수정한 뒤 테스트 결과까지 확인한다
- 여러 자료를 조사해 근거가 달린 보고서를 작성한다
- 큰 작업을 여러 에이전트에게 나누어 진행한다
단순히 '답을 알려 주는 AI'가 아니라, 목적과 작업 조건을 건네고 일을 맡기는 AI로 보면 이해가 빨라요.
큰 컨텍스트 ≠ 정확한 전달
Fable 5는 100만 토큰 컨텍스트와 128K 토큰 출력을 지원하니, 다수의 명세서나 대규모 코드베이스를 한꺼번에 다루기 수월해요. 다만 읽어 들이는 정보량이 많다는 것과 의뢰가 정확하게 전달된다는 것은 별개예요. 대량의 정보를 건네도 목적과 완료 조건이 모호하면, 모델은 '어디까지 조사할지', '무엇을 결과물로 삼을지'를 스스로 판단하게 되거든요.
자율성이 높은 만큼 '과한 작업'도 조심
Fable 5는 복잡한 의뢰를 자율적으로 진행하는 한편, 의뢰자가 생각하지 않은 범위까지 작업을 넓히기도 해요. 로그인 화면의 버그 수정만 부탁했는데 주변 코드 리팩터링, 새 공통 컴포넌트 작성, 미래의 기능 추가까지 내다본 추상화까지 해 버리는 식이죠. 변경 자체가 기술적으로 옳더라도 리뷰 범위와 테스트 범위가 넓어져 오히려 도입이 어려워지기도 합니다.
그래서 프롬프트에 이런 경계선을 넣어 두면 안심이에요.
- 문제 수정에 필요한 파일만 변경해 주세요
- 관계없는 리팩터링은 하지 마세요
- 미래의 가상 요건에 대비한 기능 추가는 불필요합니다
- 기존 설계 패턴을 우선해 주세요
고성능 모델에 세세한 절차를 일일이 명령할 필요는 없어요. 하지만 무엇을 해도 되는지만큼이나, 무엇을 하지 말아야 하는지를 알려 주는 게 핵심이에요.
프롬프트의 5가지 기본 요소
조작 절차를 수십 개 나열하기보다, AI가 판단할 수 있는 조건을 정리하는 편이 실용적이에요. 기본이 되는 건 다음 5가지입니다.
| 요소 | 적을 내용 | 예 |
|---|---|---|
| 목적 | 왜 작업하는가 | 첫 이용자의 이탈을 줄이고 싶다 |
| 결과물 | 최종적으로 무엇을 내놓는가 | 개선안을 Markdown 표로 낸다 |
| 범위 | 할 것·하지 않을 것 | UI는 대상, 인증 방식은 대상 외 |
| 완료 조건 | 어떤 상태에서 끝내는가 | 3개 안을 비교할 수 있으면 완료 |
| 검증 방법 | 무엇을 근거로 옳음을 확인하는가 | 공식 자료나 테스트 결과로 확인 |
1. 목적 — '로그인 화면을 개선한다'만으로는 디자인을 바꾸고 싶은지, 오류를 줄이고 싶은지, 가입률을 높이고 싶은지 알 수 없죠. "처음 사용하는 사람이 로그인 방법을 몰라 이탈하는 비율을 줄이기 위해, 로그인 화면의 UX 개선안을 작성해 주세요"처럼 목적을 더하면 첫 이용자가 헤매는 지점과 관련된 요소에 초점이 맞춰져요.
2. 결과물 — 형식, 대상 독자, 분량, 세분화 정도를 지정해요. '조사해 주세요'만으로는 조사 메모, 긴 보고서, 짧은 결론 목록 등 다양한 출력이 나오거든요.
결과물:
- 개선안은 3개까지
- Markdown 표로 정리한다
- 각 안에 기대 효과, 구현 비용, 리스크를 포함한다
- 전문 지식이 없는 기획 담당자도 이해할 수 있는 표현으로 쓴다
3. 범위 — 포함할 내용과 포함하지 않을 내용을 나누어 적어요. 특히 코드 변경이 따르는 작업에서는 대상 파일과 변경해도 되는 기능을 명시해 두는 걸 추천합니다.
범위:
- 대상: 화면 구성, 입력 항목, 설명문, 입력 오류 표시
- 대상 외: 인증 방식 변경, 데이터베이스 설계, 코드 구현
4. 완료 조건 — 모델이 작업을 끝내는 판단 기준이에요. 장시간 작업에서는 특히 중요하죠. 완료 조건이 없으면 추가 조사를 계속하거나, 반대로 최소한의 답변만 내고 끝내 버리기도 해요.
완료 조건:
- 현재 과제가 정리되어 있다
- 개선안이 3개 이내로 좁혀져 있다
- 각 안의 효과, 구현 비용, 리스크를 비교할 수 있다
5. 검증 방법 — 답변과 작업 결과를 무엇으로 확인할지 지정해요. 목적은 '절대 틀리지 않는 답'을 받는 게 아니라, 무엇을 확인했고 무엇을 확인하지 못했는지 보이게 만드는 거예요.
검증:
- 사양에 관한 주장은 공식 문서를 우선한다
- 코드 변경 후에는 기존 테스트를 실행한다
- 테스트하지 못한 항목은 미확인으로 명시한다
- 추측과 확인된 사실을 구분해 기재한다
장시간 작업에서 실패를 막는 지시
몇 시간 이상 걸리는 조사나 개발을 맡길 때는 일반적인 질문과는 다른 주의가 필요해요.
진행 상황 보고는 툴 결과와 대조시키기. 긴 작업에서는 '테스트가 성공했습니다'라는 보고가 정말 확인된 것인지 구별해야 해요.
진행 상황 보고 규칙:
- 보고 내용을 이번 작업에서 얻은 툴 결과와 대조해 주세요
- 실시하지 않은 작업을 완료된 것으로 다루지 마세요
- 테스트가 실패한 경우, 실패한 사실과 결과를 기재해 주세요
- 확인하지 못한 내용은 '미확인'으로 명시해 주세요
중단 조건 지정하기. 자율적으로 진행해 주길 바란다고 해서 모든 조작을 무조건 허용하는 건 위험해요. 삭제, 외부 공개, 운영 환경 반영처럼 되돌릴 수 없을 가능성이 있는 조작에서는 멈추게 해야 합니다.
다음 경우에만 작업을 중단하고 확인해 주세요.
- 파괴적이거나 되돌릴 수 없는 작업이 필요한 경우
- 처음 의뢰한 범위를 실제로 변경해야 하는 경우
- 사용자만 제공할 수 있는 정보가 필요한 경우
- 운영 환경이나 외부 서비스에 변경을 반영하는 경우
'모르는 게 있으면 뭐든 질문해 주세요'라고 적으면 작은 판단에서도 작업이 자주 멈춰요. 반대로 '절대 질문하지 말고 진행해 주세요'라고 하면 중요한 조작까지 스스로 판단해 버리죠. 멈출 조건을 구체화하는 것이 둘 사이의 균형을 잡는 방법이에요.
effort로 능력·시간·비용 조정하기. Fable 5에서는 effort가 추론 능력, 처리 시간, 비용의 균형을 조정하는 주요 수단이에요.
| 용도 | effort 기준 |
|---|---|
| 짧은 요약, 문장 바꿔 쓰기 | low / medium |
| 일반적인 조사나 설계 상담 | medium / high |
| 복잡한 설계, 긴 코드 리뷰 | high |
| 실패 시 영향이 큰 추론이나 검증 | xhigh |
항상 최대 설정을 쓰면 되는 건 아니에요. 간단한 처리에 높은 설정을 쓰면 필요 이상으로 시간과 비용이 들거든요.
생 사고 과정이 아니라 판단 이유 요구하기. Fable 5는 Adaptive Thinking이 항상 켜져 있고, 내부 사고를 그대로 돌려주는 설계가 아니에요. 필요하면 thinking.display: "summarized"를 지정해 요약된 사고 정보를 받을 수 있어요. 프롬프트에서도 '생각한 것을 전부 출력해 주세요' 대신 이렇게 의뢰합니다.
최종 판단의 이유를, 사용자에게 설명할 수 있는 범위에서 간결하게 정리해 주세요.
확인한 근거, 둔 전제, 불확실한 점을 구분해 기재해 주세요.
원하는 건 내부 사고 그 자체가 아니라 결과를 평가하기 위한 근거니까요.
그대로 쓸 수 있는 프롬프트 템플릿
지금까지의 내용을 실무용 템플릿으로 정리할게요. 모든 항목을 길게 적을 필요는 없어요. 모델이 판단을 망설일 만한 부분만 구체화해 주세요.
저는 [목적·배경]을 위해 [작업 내용]을 하고 싶습니다.
다음을 충족해 주세요.
1. 결과물
- [원하는 형식]
- [대상 독자]
- [분량과 세분화 정도]
2. 범위
- 할 일: [포함할 내용]
- 하지 않을 일: [불필요한 내용, 금지 사항]
3. 진행 방식
- 정보가 충분하면 그대로 작업해 주세요
- 정말 필요한 확인 사항만 질문해 주세요
- 판단이 어려우면 추천안을 1개 골라 진행해 주세요
4. 완료 조건과 검증
- [완료로 판단할 조건]
- 사실에는 근거를 제시해 주세요
- 불확실한 점은 불확실하다고 명시해 주세요
- 실제로 확인한 결과만 완료로 보고해 주세요
5. 출력
- 처음에 결론
- 다음에 중요한 근거
- 마지막에 남은 과제 또는 다음 액션
코드 리뷰에 적용하면 이렇게 됩니다.
이 리포지토리를 리뷰해 주세요.
목적:
운영 배포 전에 중대한 버그, 설계 실수, 보안상 우려를 찾기 위해서입니다.
결과물:
- Markdown 형식
- 중요도가 높은 지적부터 나열한다
- 각 지적에 영향, 근거, 수정안을 포함한다
범위:
- 운영 장애로 이어질 문제를 우선한다
- 스타일 수정이나 취향에 따른 리팩터링은 하지 않는다
- 사양이 불분명한 부분은 단정하지 말고 가설로 기재한다
진행 방식:
- 먼저 전체 구성을 파악한다
- 다음으로 중요한 처리를 깊이 들여다본다
- 필요하면 테스트를 실행한다
완료 조건과 검증:
- 지적에는 해당 파일이나 확인 결과를 첨부한다
- 확인하지 못한 내용은 미확인으로 명시한다
- 지적이 없는 경우에도 남은 리스크나 미실시 테스트를 적는다
우선순위, 불필요한 작업, 지적 형식, 확인하지 못했을 때의 처리까지 지정했기 때문에, 표면적인 스타일 지적만 쌓이는 걸 막고 운영에 영향이 큰 문제에 집중하기 좋아지죠.
물론 짧은 글 요약에 매번 5가지 항목을 전부 자세히 적을 필요는 없어요. 일상적인 요약이라면 이 정도로도 충분합니다.
이 문서를, 프로젝트 상황을 모르는 상사에게 보고할 수 있게 요약해 주세요.
결론, 현재 문제, 필요한 판단 순으로 300자 이내로 정리해 주세요.
본문에 없는 내용은 추측으로 보충하지 마세요.
중요한 건 템플릿을 기계적으로 채우는 게 아니라, AI가 일을 진행할 때 어디까지 스스로 판단해도 되는지를 설계하는 거예요.
마치며: 6월 22일까지가 승부
이번 발표의 핵심을 다시 짚어 볼게요.
- Fable 5와 Mythos 5는 같은 기반 모델이고, 차이는 세이프가드 유무뿐
- Opus를 넘어서는 Mythos 클래스의 일반 제공 버전이 Fable 5
- 리스크 영역(사이버·생물화학·증류)에서는 거부 대신 Opus 4.8로 폴백하는 구조
- 가격은 입력 $10·출력 $50 / 100만 토큰, 컨텍스트 100만 토큰, 최대 출력 128K
- 마이그레이션 시
thinking disabled불가,stop_reason: "refusal"처리, 30일 데이터 보존(ZDR 불가)을 점검 - 6월 22일까지는 Pro / Max / Team / 시트 기반 Enterprise 플랜에 추가 요금 없이 포함, 23일부터는 크레딧 필요
구독 플랜에서 추가 비용 없이 쓸 수 있는 게 6월 22일까지라서, 이 글의 템플릿을 부담 없이 테스트해 보기 좋은 시기예요. 개인적으로 먼저 시험해 보고 싶은 건, 과거 제 프로젝트를 Fable 5에 넘겨서 보안 문제나 찾기 어려운 버그를 찾아내게 하는 거예요. Mythos급 모델의 취약점 발견 능력을 일반 개발자가 어디까지 활용할 수 있는지 정말 궁금하거든요.
다만 보안 리뷰는 바로 사이버 분류기가 반응할 수 있는 영역이죠. 제 코드의 방어적인 리뷰가 Fable 5 본체에서 처리될지, 아니면 Opus 4.8로 폴백이 발생할지 — 이 동작의 관찰 자체까지 포함해 검증하고, 결과는 후속 기사로 정리할 예정입니다.
©2024-2026 ClaudeCode.to, Hand-crafted & made with Jaewoo Kim.
이메일문의: jaewoo@claudecode.to
Koding 프로필: https://koding.kr/u/jaewoo.kim
Jaewoo Kim by AI-fluent liberal arts Engineer
이 글이 도움이 됐다면 추천해 주세요